


Strona korzysta z plików cookie w celu realizacji usług zgodnie z Polityką Prywatności. Możesz określić warunki przechowywania lub dostępu mechanizmu cookie w Twojej przeglądarce.
PL

PL
EN
Uczenie maszynowe jest podzbiorem szerszej dziedziny sztucznej inteligencji. Dziedzina uczenia maszynowego poświęcona jest zrozumieniu i zbudowaniu systemu, który może się "uczyć". Oznacza to, że system poprawia wydajność na pewnym zestawie zadań w oparciu o określone dane.
W tradycyjnym uczeniu maszynowym, uczenie dzieli się na 3 główne grupy w oparciu o charakter sygnału lub informacji zwrotnej, są to [1]:
W uczeniu nadzorowanym algorytm próbuje znaleźć optymalną funkcję g:X→Y, która odwzorowuje dane wejściowe na dane wyjściowe.
Niech 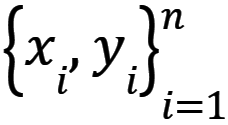 będzie zbiorem danych nadzorowanych składającym się z n próbek, gdzie xi jest wejściem (wektorem cech i-tej próbki), a yi wyjściem (klasą).
będzie zbiorem danych nadzorowanych składającym się z n próbek, gdzie xi jest wejściem (wektorem cech i-tej próbki), a yi wyjściem (klasą).
Podczas procesu uczenia dane wejściowe są podawane do systemu uczącego, a system uczący generuje dane wyjściowe 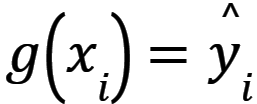 . Optymalna funkcja g jest wybierana na podstawie minimalizacji zsumowanej funkcji straty dla wszystkich elementów zbioru danych, tak aby R(g) było minimalne, gdzie R(g) jest zdefiniowane równaniem (1) [2, 3].
. Optymalna funkcja g jest wybierana na podstawie minimalizacji zsumowanej funkcji straty dla wszystkich elementów zbioru danych, tak aby R(g) było minimalne, gdzie R(g) jest zdefiniowane równaniem (1) [2, 3].
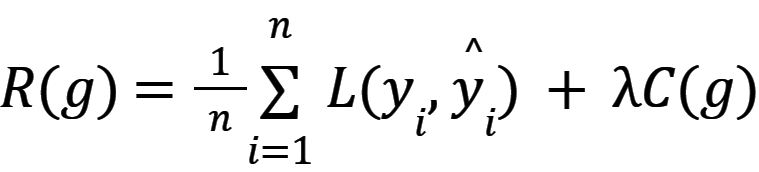
Gdzie:
λ – parametr sterujący kompromisem bias-variance.
C(g) - funkcja kary regularyzacyjnej g.
W uczeniu bez nadzoru dane wejściowe x nie są etykietowane, tzn. z=x ϵ Rd, więc algorytm uczy się wzorców w obrębie danych wejściowych. Metody uczenia bez nadzoru można podzielić na 3 grupy w zależności od zadania [4]:
Algorytmy uczenia wzmacniającego uczą agentów znajdowania sposobów wykonywania w środowisku zbioru akcji, które maksymalizują pojęcie skumulowanej nagrody. Działania dla poszczególnych agentów nazywane są mapą polityki - równanie 2 i 3 [5].
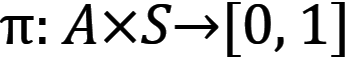
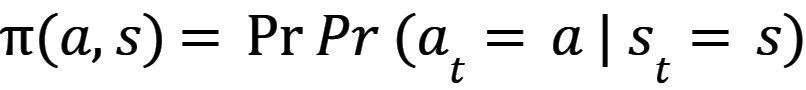
Gdzie:
a - akcja;
s - stan.
Funkcja a,s reprezentuje prawdopodobieństwo podjęcia akcji a w stanie s. Algorytm ma za zadanie znaleźć politykę, która maksymalizuje oczekiwany zwrot - funkcję wartości stanu V(s), która jest zdefiniowana równaniem (4) [5].
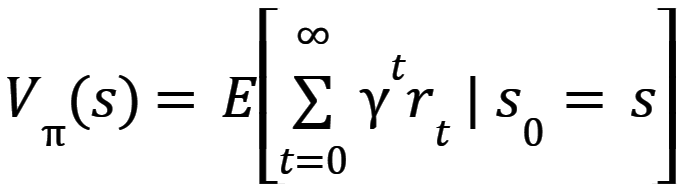
Gdzie:
t – timestep;
rt – reward;
γ ϵ [0,1) – discount-rate.
Bibliografia:
[1]
H. D. Wehle, „Machine Learning, Deep Learning, and AI: What’s the Difference?”, w Data Scientist Innovation Day, 2017.
[2]
Q. Liu I Y. Wu, „Supervised Learning,” w Encyclopedia of the Sciences of Learning, Boston, MA, Springer, 2012, s. 3243-3245.
[3]
V. Vapnik, „Principles of Risk Minimization for Learning Theory”, w Advances in Neural Information Processing Systems, The MIT Press, 1991, s. 831-838.
[4]
IBM, „What is Unsupervised Learning?”, IBM Cloud Education, 21 09 2020. [Online]. Dostępny: https://www.ibm.com/cloud/learn/unsupervised-learning. [Data uzyskania dostępu: 14 07 2022].
[5]
R. S. Sutton i A. G. Barto, Reinforcement Learning: An Introduction, MIT Press, 2018.